![]()
LLVM简介
LLVM是一个模块化的、可重用的编译器和工具链技术的集合。最开始是由克里斯·拉特纳(Chris Lattner)在伊利诺伊大学主导开发的一个研究项目,目的是提供一个现代的、基于SSA编译策略的,能够支持任意编程语言和动态编译的编译器和工具链的集合。
后来,克里斯及其他的团队被苹果雇佣了,为实现苹果系统中的各种用途而开发LLVM系统。 克里斯·拉特纳也是Swift之父,在苹果任职期间主导研发了Swift语言,编译部分也采用了LLVM工具链技术。
LLVM名称最初的由来是低级虚拟机首字母的缩写(Low Level Virtual Machine),后来由于这个解释不能准确的代表当前LLVM编译系统的强大和特别之处,LLVM系统是由众多子系统组成的包括LLVM内核、Clang编译前端、LLDB调试器、libc++标准库等等,所以官方也放弃了这个解释,而LLVM是作为整个系统的全称,这里可以参考LLVM官方网站。
传统编译器架构
传统的静态编译器最流行的就是金典的三段式设计,其主要组件是前端(Frontend)、优化器(Optimiser)、和后端(Backend)。如下图所示:

- 前端(Fontend): 主要对源代码进行词法分析、语法分析、语义分析并生成具有层级关系的抽象语语法树(AST),最后生成中间代码(IR)
- 优化器(Optimizer):优化器负责执行各种各样的转换,以尝试改进代码的运行时间,例如消除冗余代码,这个过程通常是与前后端无关的。
- 后端(Backend):主要是根据目标指令集生成机器代码,还可以根据所支持的体系结构特点,来生成适应该架构的优质代码。编译器后端常见的部分包括指令选择、寄存器分配和指令调度。
这个模型同样适用于解释器和JIT编译器。Java虚拟机(JVM - Java Virtual Machine)也是这个模型的实现,它使用Java字节码作为前端和优化器之间的接口。
LLVM三段式架构
LLVM的不同之处在于,可以作为多种前端编译器的优化器,并且可以针对多种CPU架构生成对应的机器代码。其优势就是优化器的功能可重用,适用于多种编程语言和多种CPU架构平台。如下图所示:
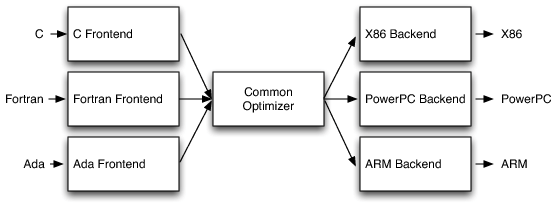
这种架构设计的优势:
- 可重用:由于前后端是分离的,当需要移植一个新语言源时,只需要实现一个新的前端,而现有的优化器和后端可以直接重用。
- 模块化:不同于其他编译器(如:GCC)的整体式设计,LLVM将各个阶段的编译技术模块化,尤其是语言无关的通用优化器,可支持多种语言输入,可输出多种架构的机器代码。
- 丰富的开发者资源:这种设计意味着它支持不止一种源语言和目标平台(如:x86、ARM、MIPS),会吸引更多的开发人员参与到该项目中,就会有更多高质量的代码产生,这自然会对编译器带来更多的增强和改进。
- 有利于分工:实现前端所需的技能与优化器、后端所需的技能不同,将它们分开可以使“前端人员”更容易地增强和维护他们的编译器部分。”后端人员“可以专注于中间代码的优化和目标平台机器代码的生成。
LLVM编译过程分析:
- 词法分析: 将源代码中的所有字符切分成记号(Token)的序列。包括了词法分析器、记号序列化生成器和扫描器,不过扫描器常常作为词法分析器的第一阶段。
- 语法分析: 分析符合一定语法规则的一串符号,它通常会生成一个抽象语法树(AST - Abstract Syntax tree),用于表示记号之间的语法关系。
- 语义分析: 通过语法分析的解析后,这个过程将从源代码中收集必要的语义信息,通常包括类型检查、在使用之前确保声明了变量等等。
- 中间代码(IR)生成:代码在这个阶段会转换为中间表示式(IR),这是一种中立的语言,与源语言(前端)和机器(后端)无关。
- 优化中间表达式。 中间代码常常会有冗余和死代码的情况出现,而优化器可以处理这些问题以获得更优异的性能。
- 生成目标代码: 最后后端会生成在目标机器上运行的机器码,我们也将其称之为目标代码。
从上述分析可以看出在LLVM架构下的编译器是如何一步一步将我们写源代码编译成机器可执行的代码的。通常,狭义的LLVM仅包括优化器和编译后端,也就是只负责IR的优化和目标代码的生成。然而,广义上的LLVM则是指所有的三个阶段、完整的编译工具链,以及一整套的SDK编译器开发技术体系,我们通常称之为:LLVM集合。
下面我们将引用一张图来表示完整的LLVM工具链集合的六大执行单元:
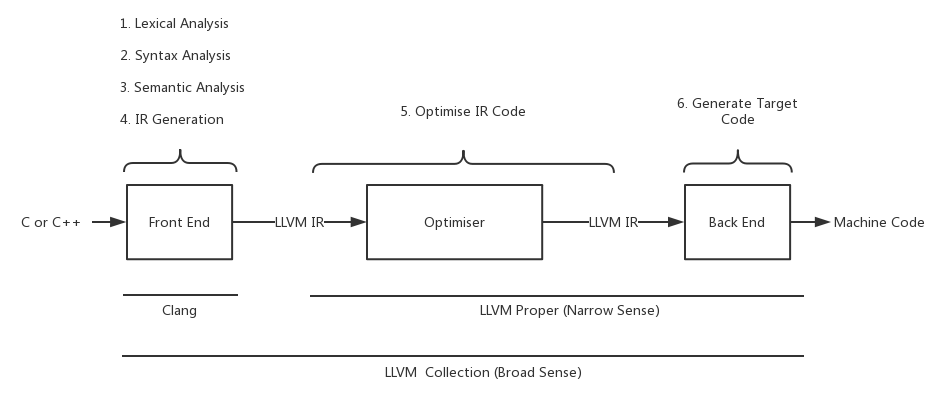
Clang
Clang是LLVM编译工具集中的一个重要成员,由C++编写,是C、C++、Objective-C/C++ 的编译前端。
Clang的开发目标是提供一个可以替代GCC的前端编译器。与GCC相比,Clang是一个重新设计的编译器前端,具有一系列优点,例如模块化,代码简单易懂,占用内存小以及容易扩展和重用等。由于 Clang 在设计上的优异性,使得 Clang 非常适合用于设计源代码级别的分析和转化工具。Clang 也已经被应用到一些重要的开发领域,如 Static Analysis 是一个基于 Clang 的静态代码分析工具。
由于 GNU 编译器套装 (GCC) 系统庞大,而且 Apple 大量使用的 Objective-C 在 GCC 中优先级较低,同时 GCC 作为一个纯粹的编译系统,与 IDE 配合并不优秀,Apple 决定从零开始写 C family 的前端,也就是基于 LLVM 的 Clang 了。Clang 由 Apple 公司开发,源代码授权使用 BSD 的开源授权。
Clang 的特性
相比于 GCC,Clang 具有如下优点:
- 编译速度快:在特定平台上,Clang 的编译速度显著的快过 GCC。
- 占用内存小:Clang 生成的 AST 所占用的内存是 GCC 的五分之一左右。
- 模块化设计:Clang 采用基于库的模块化设计,易于 IDE 集成及其他用途的重用。
- 诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告,例如Xcode中对错误精确的标红提示,以及给出快捷修复建议等。
- 设计清晰简单:容易理解,易于扩展增强,与代码基础古老的 GCC 相比,学习曲线平缓。
当前 Clang 还处在不断完善过程中,相比于 GCC, Clang 在以下方面还需要加强:
- 支持更多语言:GCC 除了支持 C/C++/Objective-C, 还支持 Fortran/Pascal/Java/Ada/Go 和其他语言。Clang 目前支持的语言有 C/C++/Objective-C/Objective-C++。
- 加强对 C++ 的支持:Clang 对 C++ 的支持依然落后于 GCC,Clang 还需要加强对 C++ 提供全方位支持。
- 支持更多平台:GCC 流行的时间比较长,已经被广泛使用,对各种平台的支持也很完备。Clang 目前支持的平台有 Linux/Windows/Mac OS。
Clang的应用
Clang作为编译前端,对源代码进行词法分析和语法分析,并将分析结果转换为抽象语法树(AST),最后生成IR中间代码提交给LLVM做下一步的优化。下面我们将从应用的角度讲一下,Clang是如何进行这些分析的。
首先,我们在终端创建一个main.m 文件,示例代码如下:
// main.m
int main(){
int a;
int b = 10;
a = b;
return a;
}
然后,Clang会对代码进行词法分析,将代码切分成Token,可通过如下命令来查看所有的Token:
clang -fmodules -E -Xclang -dump-tokens main.m
输入的Token序列打印如下:
int 'int' [StartOfLine] Loc=<main.m:2:1>
identifier 'main' [LeadingSpace] Loc=<main.m:2:5>
l_paren '(' Loc=<main.m:2:9>
r_paren ')' Loc=<main.m:2:10>
l_brace '{' Loc=<main.m:2:11>
int 'int' [StartOfLine] [LeadingSpace] Loc=<main.m:3:5>
identifier 'a' [LeadingSpace] Loc=<main.m:3:9>
semi ';' Loc=<main.m:3:10>
int 'int' [StartOfLine] [LeadingSpace] Loc=<main.m:4:5>
identifier 'b' [LeadingSpace] Loc=<main.m:4:9>
equal '=' [LeadingSpace] Loc=<main.m:4:11>
numeric_constant '10' [LeadingSpace] Loc=<main.m:4:13>
semi ';' Loc=<main.m:4:15>
identifier 'a' [StartOfLine] [LeadingSpace] Loc=<main.m:6:5>
equal '=' [LeadingSpace] Loc=<main.m:6:7>
identifier 'b' [LeadingSpace] Loc=<main.m:6:9>
semi ';' Loc=<main.m:6:10>
return 'return' [StartOfLine] [LeadingSpace] Loc=<main.m:8:5>
identifier 'a' [LeadingSpace] Loc=<main.m:8:12>
semi ';' Loc=<main.m:8:13>
r_brace '}' [StartOfLine] Loc=<main.m:9:1>
eof '' Loc=<main.m:9:2>
这个命令的作用是,显示每个 Token 的类型、值,以及位置。包括:关键字(比如:if、else、for…)、标识符(变量名)、字面量(值、数字、字符串)、特殊字符(加减乘除符号等)。
接下来,会进行语法分析,将输出的Token先按照语法组合成语义,生成节点,然后将这些节点按照层级关系构成抽象语法树(AST)。
在终端中执行如下命令即可看到main.m 文件源码的语法树:
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m
输出的AST代码如下所示:
TranslationUnitDecl 0x7fbae500c0e8 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x7fbae500c660 <<invalid sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x7fbae500c380 '__int128'
|-TypedefDecl 0x7fbae500c6d0 <<invalid sloc>> <invalid sloc> implicit __uint128_t 'unsigned __int128'
| `-BuiltinType 0x7fbae500c3a0 'unsigned __int128'
|-TypedefDecl 0x7fbae500c770 <<invalid sloc>> <invalid sloc> implicit SEL 'SEL *'
| `-PointerType 0x7fbae500c730 'SEL *'
| `-BuiltinType 0x7fbae500c5c0 'SEL'
|-TypedefDecl 0x7fbae500c858 <<invalid sloc>> <invalid sloc> implicit id 'id'
| `-ObjCObjectPointerType 0x7fbae500c800 'id'
| `-ObjCObjectType 0x7fbae500c7d0 'id'
|-TypedefDecl 0x7fbae500c938 <<invalid sloc>> <invalid sloc> implicit Class 'Class'
| `-ObjCObjectPointerType 0x7fbae500c8e0 'Class'
| `-ObjCObjectType 0x7fbae500c8b0 'Class'
|-ObjCInterfaceDecl 0x7fbae500c990 <<invalid sloc>> <invalid sloc> implicit Protocol
|-TypedefDecl 0x7fbae500ccf8 <<invalid sloc>> <invalid sloc> implicit __NSConstantString 'struct __NSConstantString_tag'
| `-RecordType 0x7fbae500cb00 'struct __NSConstantString_tag'
| `-Record 0x7fbae500ca60 '__NSConstantString_tag'
|-TypedefDecl 0x7fbae500cd90 <<invalid sloc>> <invalid sloc> implicit __builtin_ms_va_list 'char *'
| `-PointerType 0x7fbae500cd50 'char *'
| `-BuiltinType 0x7fbae500c180 'char'
|-TypedefDecl 0x7fbae5043688 <<invalid sloc>> <invalid sloc> implicit __builtin_va_list 'struct __va_list_tag [1]'
| `-ConstantArrayType 0x7fbae5043630 'struct __va_list_tag [1]' 1
| `-RecordType 0x7fbae50434a0 'struct __va_list_tag'
| `-Record 0x7fbae5043400 '__va_list_tag'
`-FunctionDecl 0x7fbae5043730 <main.m:2:1, line:9:1> line:2:5 main 'int ()'
`-CompoundStmt 0x7fbae5043a80 <col:11, line:9:1>
|-DeclStmt 0x7fbae50438a0 <line:3:5, col:10>
| `-VarDecl 0x7fbae5043840 <col:5, col:9> col:9 used a 'int'
|-DeclStmt 0x7fbae5043950 <line:4:5, col:15>
| `-VarDecl 0x7fbae50438d0 <col:5, col:13> col:9 used b 'int' cinit
| `-IntegerLiteral 0x7fbae5043930 <col:13> 'int' 10
|-BinaryOperator 0x7fbae5043a00 <line:6:5, col:9> 'int' '='
| |-DeclRefExpr 0x7fbae5043968 <col:5> 'int' lvalue Var 0x7fbae5043840 'a' 'int'
| `-ImplicitCastExpr 0x7fbae50439e8 <col:9> 'int' <LValueToRValue>
| `-DeclRefExpr 0x7fbae50439a8 <col:9> 'int' lvalue Var 0x7fbae50438d0 'b' 'int'
`-ReturnStmt 0x7fbae5043a68 <line:8:5, col:12>
`-ImplicitCastExpr 0x7fbae5043a50 <col:12> 'int' <LValueToRValue>
`-DeclRefExpr 0x7fbae5043a28 <col:12> 'int' lvalue Var 0x7fbae5043840 'a' 'int'
其中TranslationUnitDecl是根节点,表示一个编译单元;Decl表示一个声明;Expr表示的是表达式;Literal表示字面量,是一个特殊的Expr;Stmt表示语句。
Optimiser
通过上述Clang的介绍,以及Clang是如何将main.m文件中的源代码一步步转换为AST的,最后Clang会将AST 转换为中间代码IR,交由优化器(Optimiser)来做代码优化。

从上图可以看出,在LLVM IR优化阶段,优化器被设计为由若干个Pass组成的集合,每个优化模块(Pass)都能读入IR,完成一些任务后,输出优化后的IR。
常见优化模块的例子是内联优化,它会将函数体替换为调用点(call sites),还可以将表达式重新组合(expression reassociation)、移动循环不变代码(loop-invariant code motion)等等。根据优化级别的不同,可以调用不同的优化模块:例如,Clang编译器使用-O0(无优化状态)参数进行编译时不调用pass,在使用-O3时将会调用67个pass来进行IR的优化(从LLVM 2.8开始)。
由于优化器的模块化设计,Pass也可以进行自主开发,实现对LLVM 优化器的改进和增强。
总结
本文讲解了LLVM编译器工具集的历史和由来,以及作为现代应用最广泛的编译器之一,介绍了其优良的架构设计,可重用的模块化构建思想。同时,也介绍了Clang编译前端的特性已及编译过程的举例分析。
通过对LLVM编译工具集的学习,深刻的感受到 了它的强大之处,先进的设计理念,想必能在以后的编程中提升对代码优化、底层思维逻辑的理解能力。
希望和我一样对LLVM编译器感兴趣的同学,能学习到对自己有用的知识,提高对编程的底层认知能力。